从 Tesla AI Day 看自动驾驶的进展
零、前言
现实世界往往不能通过简单的 2D 图像去近似,最直观的想法就是加维度。时间上加维度就是视频,空间上再加维度就是 3D 数据例如点云,在其他属性上加维度就是多模态。真实场景遇到的数据是会更具挑战性的。而自动驾驶就是这样的典型场景,下面通过 Tesla AI Day 的 Tesla Vision 部分去介绍一下 Tesla 自动驾驶的感知方案。
地址:https://www.youtube.com/watch?v=j0z4FweCy4M
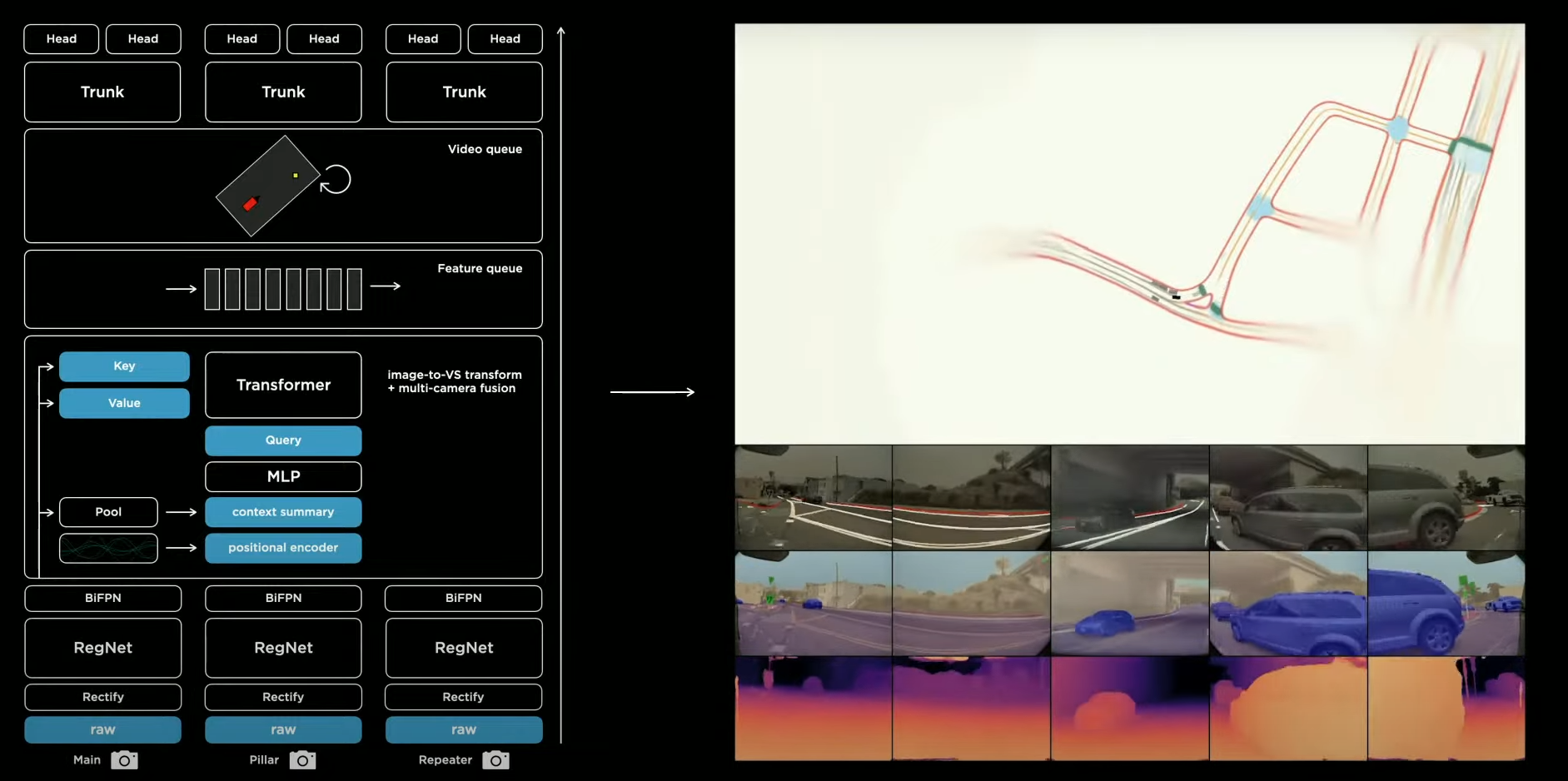
一、单帧感知任务的基础网络架构:HydraNets

1、Raw 格式图像特征输入
输入是 Raw 格式的图像,参数为 1280x960 12-Bit (HDR) @ 36 Hz
2、特征提取模块
Backbone 为 RegNet 输出 Multi-scale 的输出,分为四路,其分辨率分别为:160x120x64、80x60x128、40x30x256、20x15x512
3、特征增强模块
BiFPN 接收 Multi-scale Feature 进行特征增强
4、任务相关的 Head
经过特征的提取和增强,后面接多个 Head 负责不同的任务,以下用目标检测举例:
对于目标检测,使用类似 Yolo 的单阶段检测器,
- 类别分支输出 640 x 480 x 1 的类别预测
- 回归分支输出 640 x 480 x 4 的框的位置
- 属性分支输出感兴趣的属性
不仅是目标检测,还有交通灯任务、车道线预测等任务。每一个 Head 都接收同样的 multi-scale features 作为输入,每个 Head 内部去对 Feature 做处理,Tesla 将其称之为 Multi-Task Learning "HydraNets"
5、网络架构的优势
- Feature Sharing:在推理时只需要过一遍,比较高效
- De-Couples Tasks:可以去独立地去 Fine-Tune 每个子任务
- Represemtation Bottleneck:能够做一个 Feature Cache 的操作,将 Feature 存到硬盘中,能够加速 Fine-Tuning Head 的进程
6、基于单帧图像的推理结果

单帧的预测结果如上图:
- 识别到的目标有车道线,红绿灯,车的三维框,交通标志等
- 识别到的属性有目标三维框,距离等
二、从 Image Space 到 Vector Space 转换:多传感器融合
1、单相机独立检测后融合的劣势


这部分听的不是特别懂,大概的意思是想将 Image Space 转到 Vector Space 上。而单摄像头独立预测后建出的 Vector Space 存在偏差和目标不连续的情况,不太可靠,使用多摄像头的信息会更加好。上图为单摄像头组成的 Vector Space,以及多摄像头的检测结果。
2、多相机的向量空间特征融合的难点
能想到的做法就是把八张图像先输入到 RegNet 和 BiFPN 得到 multi-scale Features,但是仍然存在两个问题
- 如何将 Image Space 的特征 转化为 Vector Space 的特征
- Vector space 的预测结果需要 vector space 的数据集,但这很难获得
3、解决第一个问题:图像空间到向量空间

不同相机中的图像中同一个点如何进行标定?
- 不同相机的位置直接用 Transformer 的位置编码去实现
- 使用 Transformer 去表示这个空间
- 使用不同相机的特征作为 Transformer 模块的 key 和 value 输入,而特征进行 pool 之后进行上下文特征的聚合再经过 MLP 可以得到 Query
4、多机位相机校准
Variations in Camera Calibration
这一段听的不是很懂,主题是讲相机标定的
Rectify to a Common Virtual Camera
也不是很懂,通过标定之后,会使得图像变得更加清晰
5、多相机融合后的 Vector Space 以及预测结果


上图一是通过多传感器融合后的 Vector Space 中的 Edges 和 Lines,更加完整和稳定。上图二是通过多传感器融合后的检测结果,会更加准确和稳定
三、如何依赖时序上下文做出预测呢:插入 Video Module
1、整体方案概览

- 先得到 Multi-cam features,维度是 20 x 80 x 256
- 放入我们的 Feature Queue 中,队列中的维度是 20 x 80 x 256 x60
- Video Module 用于对带有时间信息的特征进行一个融合
2、Feature Queue
- Temporary occlusions:使用基于时间的 queue,每 27ms 就 push 一次 feature,有利于解决遮挡问题
- Signs & Line Markings Earlier on the Road:使用基于空间的 queue,每 1m 就 push 一次feature,有利于更好地利用交通信号等信息来预测未来道路,而不会因为只有 time-based queue 丢失特征的情况
3、Video Modules

Video Modules 分为三部分:3D 卷积,Transformer,RNN。三部分的输出维度都是 20 x 80 x 300。讲者重点介绍了 Spatial RNN,但我还是听的不太明白。大概是通过对特征进行空间上的 RNN,可以做成以下两件事情:
- 对遮挡物体有很好的重识别
- 可以拿来建高精地图
Video Modules 的作用
- 使得目标检测的预测更加的可靠,还可以检测出被遮挡的物体
- 与雷达相比,都可以较为准确的衡量深度和速度
四、整体方案

总的下来,真的就是针对自动驾驶的感知任务去做了较为鲁棒的方案,在我的眼里就和前言说的一样,将 2D 图像不断地扩展,目前来讲,Tesla 不想上激光雷达所以还没有点云的处理模块,但是有多相机和时间维度的处理方案。总的来说分为以下四个点:
- 特征提取部分:融合多尺度信息
- 时序信息:设计 Video Module
- 多相机:设计多相机特征融合模块
- 多 Head:负责多个感知任务
五、感想
总的来讲,Tesla 非常真诚地分享了自己的方案,每个方向去递进地做,做法都很合理,即使细节不那么充实的方案,讲述之后都让我收益良多。或许实习会去做自动驾驶的感知业务,希望能为自动驾驶业务贡献自己的一份力量,也希望我能够去真正在实际业务上去学习,去成长。最近会看一些半监督语义分割的工作,可能会去做数据闭环。再会!
